
O Búsqueda profunda V4 se lanzó el 24 de abril de 2026 como la mayor actualización jamás realizada por el laboratorio chino de inteligencia artificial.
Es una familia de dos modelos: V4-Pro Y V4-Flash – código completamente abierto, con licencia del MIT.
Ambos vienen con una ventana contextual. 1 millón de fichas y precios que desafían directamente los modelos propietarios occidentales.
El lanzamiento se produjo el mismo día en que GPT 5.5 dominaba las discusiones, y eso no fue una coincidencia.
¿Qué es DeepSeek V4 y cuáles son sus variantes?
O Búsqueda profunda V4 Es el cuarto modelo de la serie insignia de DeepSeek, que reemplaza permanentemente al V3 y al V3.2.
Los dos modelos de la familia presentan arquitectura. Mezcla de Expertos (MoE)que activa solo una fracción de los parámetros por token.
O DeepSeek V4-Pro temperatura 1,6 billones de parámetros totales com 49 mil millones en activos por tokenpre-entrenado en 33 billones de tokens.
Esto lo convierte en el más grande modelo de peso abierto actualmente disponible: más grande que el Kimi K2.6 (1.1T) y más del doble que el DeepSeek V3.2 (671B).
O DeepSeek V4-Flash temperatura 284 mil millones de parámetros totales com 13 mil millones en activos por tokenentrenado con 32 billones de tokens.
Ambos soportan ventana de contexto. 1 millón de fichas con máxima potencia de 384.000 fichas — tres veces más que Claude Opus 4.7 y GPT 5.4, que limitan la producción a 128.000 tokens.
Los pesos para ambos modelos están disponibles de forma gratuita en Hugging Face y la API estuvo disponible el día del lanzamiento.
Tres modos de razonamiento
DeepSeek V4 ofrece tres modos de funcionamiento: No pensado para respuestas rápidas, Pensamiento para el razonamiento estándar e Piensa en Max para el máximo esfuerzo en tareas complejas.
En el modo Think Max, el modelo recibe un presupuesto ampliado de tokens de razonamiento, lo que mejora el rendimiento en matemáticas avanzadas y tareas difíciles de los agentes.
Para el modo Think Max, DeepSeek recomienda configurar la ventana contextual al menos 384.000 fichas.
Arquitectura: lo que ha cambiado respecto a la V3.2
La innovación arquitectónica más relevante en Búsqueda profunda V4 es el mecanismo de la atención híbrida.
El modelo combina Atención dispersa comprimida (CSA) Y Atención muy comprimida (HCA) para manejar contextos largos con costos computacionales mucho más bajos.
En 1 millón de contextos de tokens, V4-Pro solo usa 27% dos fracasos inferencia de un solo token e 10% de la memoria caché KV en comparación con V3.2.
El V4-Flash va aún más allá: sólo utiliza 10% dos fracasos Y El 7% usa caché KV en comparación con V3.2 en el mismo contexto de token de 1 millón.
Además, el modelo incorpora Hiperconexiones vinculadas a coleccionistas (mHC) para mejorar la estabilidad en la propagación de la señal entre capas.
Otra innovación es el uso del optimizador. muón durante el entrenamiento, lo que acelera la convergencia.
Todos estos cambios hacen que DeepSeek V4 sea estructuralmente más eficiente, no sólo más grande.
Precio: la ventaja más obvia de DeepSeek V4
La diferencia de precio entre el Búsqueda profunda V4 y los modelos propietarios son expresivos.
O V4-Flash costos 0,14 dólares por millón de tokens al entrar Y 0,28 dólares por millón al salir – haciéndolo más barato que GPT-5.4 Nano, Gemini 3.1 Flash y Claude Haiku 4.5.
O V4-Pro costos 1,74 dólares por millón de tokens al entrar Y 3,48 dólares por millón a la salida – acerca de 7 veces más barato en comparación con GPT 5.5 y Claude Opus 4.7.
Los accesos a la caché solo se cobran 20% de la tarifa de inscripción estándarlo que genera importantes ahorros en aplicaciones con instrucciones repetitivas.
Para los equipos que procesan grandes volúmenes de texto, la diferencia es aún más significativa en la práctica.
A IA china mantiene su tradición de precios agresivos, y el V4 lo hace sin comprometer su capacidad para competir con modelos de gama alta.
Punto de referencia: dónde se encuentra DeepSeek V4
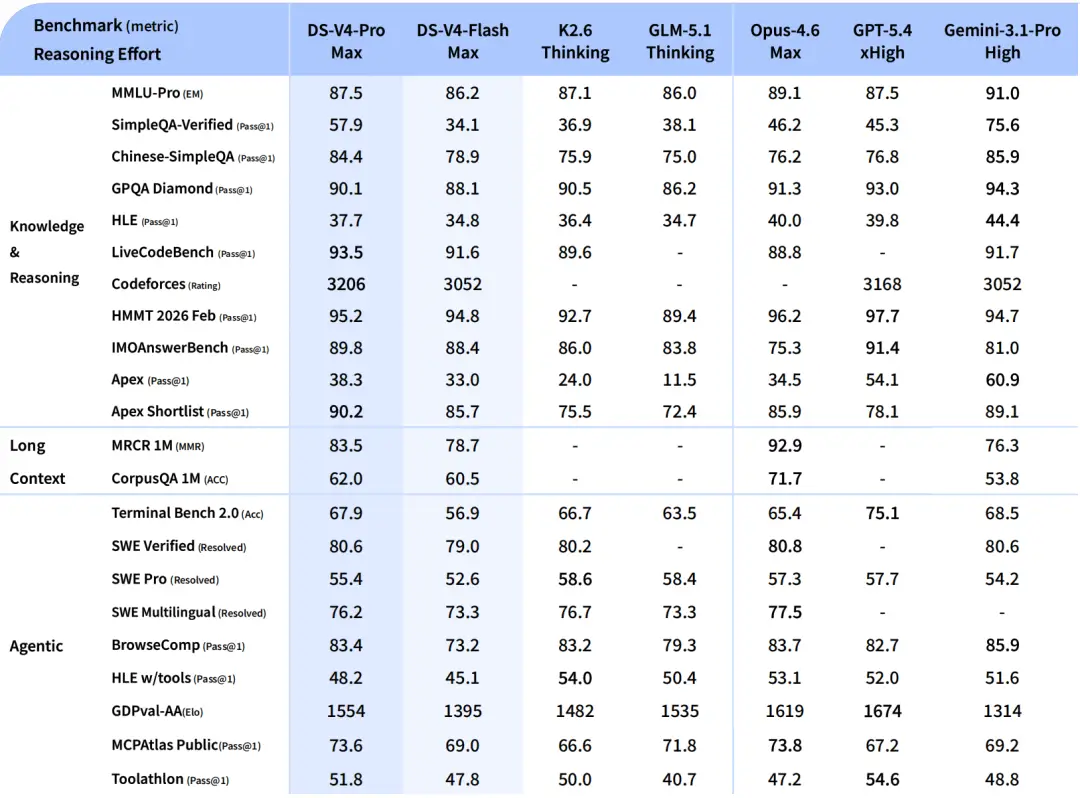
Los puntos de referencia del sistema operativo hacen esto Búsqueda profunda V4 Muestran un modelo muy cercano al de los líderes occidentales, sobre todo teniendo en cuenta su precio.
Terminal-Banco 2.0
En Terminal-Bench 2.0, un punto de referencia de flujo de trabajo de línea de comandos que involucra planificación, iteración y coordinación de herramientas, el V4-Pro logró 67,9% y el V4-Flash anotó 56,9%.
A modo de comparación, GPT 5.5 está por delante 82,7% y Claude Opus 4.7 grabado 69,4%.
El V4-Pro está sólo 1,5 puntos porcentuales por debajo del Opus 4.7 en este punto de referencia de agente, a una fracción del precio.
Banco SWE verificado
En SWE-bench Verified el resultado está aún más cerca de la competencia.
El DeepSeek V4-Pro logró 80,6% y el V4-Flash anotó 79,0% – contra 80,8% hacer Claude Opus 4.6.
La diferencia entre V4-Pro y Opus 4.6 es simplemente 0,2 puntos porcentuales en este punto de referencia de desarrollo de software.
Vale la pena señalar que Claude Opus 4.7, el lanzamiento más reciente de Anthropic, obtuvo una puntuación 87,6% en SWE-bench Verified: abre un margen mayor que el V4-Pro en esta categoría.
Banco SWE Pro
En SWE-bench Pro, se registró la versión más difícil del punto de referencia de resolución de problemas del mundo real de GitHub, V4-Pro 55,4% y/o V4-Flash 52,6%.
El Claude Opus 4.7 es el líder en esta categoría con 64,3%y GPT 5.5 logrado 58,6%.
LiveCodeBench y concurso de programación
En LiveCodeBench Pass@1, V4-Pro logró 93,5% y/o V4-Flash 91,6% – ambos muy por encima del Gemini 3.1 Flash y el GPT-5.4 Mini.
En Codeforces, V4-Pro se pone al día votar 3.206ubicándose entre los 23 principales competidores humanos en la plataforma.
Orquestación de herramientas: MCPAtlas y Toolathlon
NO Atlas MCPA público —Parámetro de escalabilidad de orquestación de herramientas de IA: puntuación V4-Pro 73,6%quedando a sólo 0,2 puntos del Claude Opus 4.6-Max (73,8%).
NO Atlón de herramientasel V4-Pro grabado 51,8%superando al Kimi K2.6 (50,0%), el GLM-5.1 (40,7%) y el Gemini 3.1 Pro (48,8%).
Estos resultados muestran que V4-Pro es competitivo en tareas de agentes basadas en herramientas, no solo en codificación.
Matemáticas y cultura general.
- En modo V4-Pro-Max, el modelo logra 95,2% en febrero HMMT 2026, frente al 96,2% de Claude Opus 4.6 y el 97,7% de GPT-5.4 en este mismo punto de referencia.
- Sin marca HLE (Último examen de la humanidad) ni V4-Pro 37,7%cayendo por debajo de Claude Opus 4.6 (40,0%), GPT-5.4 (39,8%) y Gemini 3.1 Pro (44,4%).
- Sin registros SimpleQA-Verified o V4-Pro 57,9% contra 75,6% de Géminis, lo que revela una brecha significativa en la recuperación de conocimiento fáctico.
DeepSeek estima que este retraso equivale a 3 a 6 meses en comparación con los modelos occidentales de vanguardia del momento.
Velocidad y rendimiento para uso en desarrollo
Para aquellos que usan LLM En el desarrollo de software, la velocidad de respuesta es tan importante como la calidad.
- O V4-Flash entrega 82,7 tokens por segundo con tiempo hasta la primera ficha 1,04 segundos — velocidad muy por encima de la media de los modelos abiertos de tamaño similar (56,5 t/s).
- O V4-Pro funciona a aprox 36,8 fichas por segundo con latencia de 1,28 segundos — ritmo comparable al Claude Opus 4.7, que varía entre 35 y 43 tokens por segundo.
Por tanto, DeepSeek V4 Pro llega al mercado con una velocidad competitiva desde su lanzamiento, algo que otros modelos de código abierto los más grandes, como el Kimi K2.6 y el GLM, generalmente no pueden entregarse de inmediato.
O Búsqueda profunda V4 se integró de forma nativa con herramientas de desarrollo de agentes como Código Claudio, garra abierta Y código abierto.
La API admite formatos. Finalizaciones del chat OpenAI Y API antrópica – lo que significa que la integración no requiere cambiar la URL base, sino solo actualizar el parámetro de la plantilla.
Para aquellos que usan OpenRouter, el acceso a V4-Pro y V4-Flash ahora está disponible, lo que les permite conectar su modelo a arneses como Claude Code, VS Code y Cursor.
Una nota importante para los desarrolladores: plantillas chat de búsqueda profunda Y razonador de búsqueda profunda será detenido más tarde 24 de julio de 2026. Las migraciones deben realizarse a ID explícitos. deepseek-v4-pro O deepseek-v4-flash antes de esa fecha.
Limitaciones importantes de DeepSeek V4
O Búsqueda profunda V4 solo admite texto como entrada y salida.
A diferencia de GPT 5.5 y Gemini 3.1 Pro, no procesa audio, vídeo ni imágenes.
Esto limita su uso en flujos de trabajo multimodales, como analizar pantallas de interfaz, generar imágenes o interpretar diagramas visuales.
Además, el V4-Pro en modo de razonamiento máximo es bastante detallado y genera muchos más tokens por respuesta que el promedio de los modelos de la competencia.
Para el autohospedaje, V4-Flash es el objetivo práctico: con 284 mil millones de parámetros y 13 mil millones de recursos por token, se adapta a configuraciones de múltiples GPU asequibles para equipos de tamaño mediano.
V4-Pro, con 1,6 billones de parámetros totales, requiere una importante infraestructura de clúster: la mayoría de los equipos utilizarán la API DeepSeek para Pro.
¿Vale la pena DeepSeek V4 para el desarrollo de software real?
La respuesta depende del tipo de tarea y del presupuesto disponible.
En puntos de referencia de desarrollo de software como SWE-bench Verified y LiveCodeBench, el V4-Pro se acerca mucho al Claude Opus 4.6 a una fracción del precio.
En orquestación de instrumentos a través de MCPAtlas y Toolathlon, DeepSeek V4 Pro supera a Gemini 3.1 Pro y se acerca a Opus 4.6.
En las tareas de agente más complejas en Terminal-Bench y en el conocimiento factual, GPT 5.5 y Claude Opus 4.7 todavía están por delante con un margen.
Sin embargo, la relación rendimiento por dólar DeepSeek V4 es difícil de ignorar para los equipos que trabajan con un gran volumen de solicitudes o que buscan reducir costos sin sacrificar la calidad de vanguardia.
Para proyectos que comienzan desde cero, V4-Pro a través de API ya demuestra la capacidad de crear aplicaciones funcionales complejas en una sola sesión, aprovechando la ventana de salida de 384.000 tokens, tres veces mayor que la de los competidores propietarios.
O modelo de código abierto La tecnología más potente disponible hoy en día llega con un argumento claro: inteligencia a un nivel cercano a la frontera, con código abierto y un precio asequible.
Ultimas Entradas Publicadas

genera tus propias imágenes AI (+4 alternativas)

las nuevas herramientas AI Playground

Cómo utilizar la IA para analizar el comportamiento del cliente y lograr mejores conversiones

Guía completa para autónomos eficaces

Cómo utilizar la IA para cerrar ventas importantes más rápido

Chatbots y asistentes virtuales impulsados por IA: el secreto para una mejor experiencia del cliente

Cómo la IA para la toma de decisiones le ayuda a tomar mejores decisiones en su vida personal y profesional (Guía práctica 2026)

Cree vídeos de productos realistas con avatares generados por IA

IA para diseño UX/UI: pruebas rápidas y optimización
